gemini-balance - Gemini(Google AI) API 轮询代理服务
https://github.com/snailyp/gemini-balance
Gemini Balance 是一个基于 Python FastAPI 构建的应用程序,旨在为 Google Gemini API 提供代理和负载均衡功能。
● 支持配置多个 Gemini API 密钥,实现自动顺序轮询,提高可用性和并发性
● 通过管理后端即时生效的可视化配置
● 支持以 Gemini 和 OpenAI 格式转发 CHAT API 请求
● 支持图像 - 文本聊天和图像编辑功能
● 支持网页搜索功能
● 提供实时查看每个密钥状态和使用情况的 /keys_status 页面
● 提供详细的错误日志,便于故障排查
● 支持自定义 Gemini 代理
● 兼容 OpenAI 图像生成 API
● 灵活的密钥添加方式,支持正则匹配
● 完美适配 OpenAI 格式的嵌入 API 接口
● 可选的流响应优化功能
● 自动处理 API 请求失败、重试和密钥管理
● 支持 AMD 和 ARM 架构的 Docker 部署
● 支持自动获取 OpenAI 和 Gemini 模型列表
● 支持配置 HTTP/SOCKS5 代理服务器
#AI #Google #Tool #GitHub
https://github.com/snailyp/gemini-balance
Gemini Balance 是一个基于 Python FastAPI 构建的应用程序,旨在为 Google Gemini API 提供代理和负载均衡功能。
● 支持配置多个 Gemini API 密钥,实现自动顺序轮询,提高可用性和并发性
● 通过管理后端即时生效的可视化配置
● 支持以 Gemini 和 OpenAI 格式转发 CHAT API 请求
● 支持图像 - 文本聊天和图像编辑功能
● 支持网页搜索功能
● 提供实时查看每个密钥状态和使用情况的 /keys_status 页面
● 提供详细的错误日志,便于故障排查
● 支持自定义 Gemini 代理
● 兼容 OpenAI 图像生成 API
● 灵活的密钥添加方式,支持正则匹配
● 完美适配 OpenAI 格式的嵌入 API 接口
● 可选的流响应优化功能
● 自动处理 API 请求失败、重试和密钥管理
● 支持 AMD 和 ARM 架构的 Docker 部署
● 支持自动获取 OpenAI 和 Gemini 模型列表
● 支持配置 HTTP/SOCKS5 代理服务器
#AI #Google #Tool #GitHub
Gemini Fullstack LangGraph Quickstart
https://github.com/google-gemini/gemini-fullstack-langgraph-quickstart
项目展示了如何使用 LangGraph 和 Google 的 Gemini 2.5 模型构建全栈 AI Agent,通过动态生成搜索词、使用 Google 搜索查询网页、反思结果以识别知识差距并迭代地改进搜索,最终提供有依据的答案和引用来完成对用户查询的全面研究,让复杂问题一键解决。
● 使用 React 前端和 LangGraph 后端构建的全栈应用程序
● 由 LangGraph 代理提供 Deep Research 和对话 AI 功能
● 使用 Google Gemini 模型动态生成搜索查询
● 通过 Google 搜索 API 集成网络研究
● 使用反思推理识别知识差距并完善搜索
● 生成带有引用来源的答案
● 开发过程中前后端都支持热重载
#AI #GitHub #Tool #Google
https://github.com/google-gemini/gemini-fullstack-langgraph-quickstart
项目展示了如何使用 LangGraph 和 Google 的 Gemini 2.5 模型构建全栈 AI Agent,通过动态生成搜索词、使用 Google 搜索查询网页、反思结果以识别知识差距并迭代地改进搜索,最终提供有依据的答案和引用来完成对用户查询的全面研究,让复杂问题一键解决。
● 使用 React 前端和 LangGraph 后端构建的全栈应用程序
● 由 LangGraph 代理提供 Deep Research 和对话 AI 功能
● 使用 Google Gemini 模型动态生成搜索查询
● 通过 Google 搜索 API 集成网络研究
● 使用反思推理识别知识差距并完善搜索
● 生成带有引用来源的答案
● 开发过程中前后端都支持热重载
#AI #GitHub #Tool #Google
Google AI Studio 体验下一代 AI 模型 Kingfall
来源:Google AI Studio 模型注入脚本:原理、开发与调试全指南
安装帖子中的油猴脚本,之后打开 AI Studio 即可体验 Kingfall / Gemini 2.5 Pro-0325(出道即巅峰)
#AI #Google #Script
来源:Google AI Studio 模型注入脚本:原理、开发与调试全指南
安装帖子中的油猴脚本,之后打开 AI Studio 即可体验 Kingfall / Gemini 2.5 Pro-0325(出道即巅峰)
#AI #Google #Script
Gemini 2.5 Pro 0605 现已在 AI Studio 可用,宣称在多个基准测试中回到 SOTA 水平。
#Google #AI
https://deepmind.google/models/gemini/pro/
#Google #AI
https://deepmind.google/models/gemini/pro/

Google AI Edge Gallery - 在手机本地运行 AI 模型的 App
https://github.com/google-ai-edge/gallery
类似于之前看到的阿里推出的 MNN,暂时支持的模型没有 MNN 多
目前支持 Android ,并将晚些时间支持 iOS。
Google 出品的允许用户在手机上运行 AI 大模型的 App。它可以运行来自 AI 开发平台 Hugging Face 的一系列公开 AI 模型。
用户可以通过它查找、下载和运行兼容的模型,这些模型可以生成图像、回答问题、编写和编辑代码等等。这些模型可以离线运行,无需网络连接,并利用受支持的手机处理器。该应用主屏幕显示 AI 任务和功能的快捷方式。其还提供了一个“Prompt Lab”,用户可以使用它来启动由模型驱动的 “单轮” 任务,例如摘要和文本重写。Prompt Lab 附带多个任务模板和可配置设置,用于微调模型的行为。
—— TechCrunch
#Google #AI #Tool #Android #GitHub #RePost link
https://github.com/google-ai-edge/gallery
类似于之前看到的阿里推出的 MNN,暂时支持的模型没有 MNN 多
目前支持 Android ,并将晚些时间支持 iOS。
Google 出品的允许用户在手机上运行 AI 大模型的 App。它可以运行来自 AI 开发平台 Hugging Face 的一系列公开 AI 模型。
用户可以通过它查找、下载和运行兼容的模型,这些模型可以生成图像、回答问题、编写和编辑代码等等。这些模型可以离线运行,无需网络连接,并利用受支持的手机处理器。该应用主屏幕显示 AI 任务和功能的快捷方式。其还提供了一个“Prompt Lab”,用户可以使用它来启动由模型驱动的 “单轮” 任务,例如摘要和文本重写。Prompt Lab 附带多个任务模板和可配置设置,用于微调模型的行为。
—— TechCrunch
#Google #AI #Tool #Android #GitHub #RePost link
Google Stitch
https://stitch.withgoogle.com/
号称是生成出色设计和 UI 界面最简单、最快捷的产品
Stitch是一个 AI 驱动的工具,帮助应用程序构建器为移动和 Web 应用程序生成高质量的用户界面,并轻松将它们导出 Figma,或直接访问前端代码。
#Google #AI link
https://stitch.withgoogle.com/
号称是生成出色设计和 UI 界面最简单、最快捷的产品
Stitch是一个 AI 驱动的工具,帮助应用程序构建器为移动和 Web 应用程序生成高质量的用户界面,并轻松将它们导出 Figma,或直接访问前端代码。
#Google #AI link

谷歌今天在 I/O 2025 大会上宣布了一系列新的 AI 模型、工具和订阅服务
生成媒体
- Veo 3 是 Google 最先进的视频生成模型,能够创建带有音效甚至对话的视频,目前在美国,Google AI Ultra 订阅用户可以通过 Gemini 应用和 Flow 使用,也可以在 Vertex AI 上进行私人预览,并将在未来几周内更广泛地推出
- Veo 2 正在获得新功能,例如参考驱动的视频(用于一致的风格和角色)、用于精确镜头调整的相机控制、用于扩展纵横比的外画以及对象添加/删除,现在 Flow 中提供了一些新控件,而 Vertex AI 即将提供全套控件
- Imagen 4 可生成更丰富、更细致、更准确的图像,改进文本渲染和快速结果,现已在 Gemini 应用程序、Whisk、Workspace(幻灯片、文档、视频)和 Vertex AI 中免费提供,新的快速版本即将推出
- Flow 是一款全新的 AI 电影制作工具,可让您通过自然语言和资产管理,使用 Veo、Imagen 和 Gemini 创建电影剪辑;现在可供美国的 Google AI Pro 和 Ultra 订阅用户使用
- Google 的音乐生成模型 Lyria 2 现已在 Vertex AI 中上线,用于高保真自适应音乐生成,Lyria RealTime 可作为实验性交互式音乐模型通过 Gemini API 和 Google AI Studio 使用,用于实时创作和演奏生成音乐
Gemini 应用程序
- Canvas 新增一键“创建”按钮,可轻松将聊天内容转换为交互式内容,例如信息图表、测验和 45 种语言的播客,而 Deep Research 现在可让您上传文件和图像,并且即将推出 Google Drive 和 Gmail 集成
- Gemini Live 相机和屏幕共享功能现已在 Android 和 iOS 上免费提供(正在推出),并将很快与日历、Keep、地图和 Tasks 等 Google 应用集成
订阅
- Google AI Pro(每月 19.99 美元)可在美国和其他国家/地区使用,但一些最新功能(如 Chrome 中的 Flow 或 Gemini)将首先在美国推出,并计划在更广泛的范围内推出
- Google AI Ultra(249.99 美元/月,新用户前三个月可享受 50% 的优惠)提供最高的使用限制、最早使用 Veo 3 和 Gemini 2.5 Pro Deep Think 等高级模型、最高限制的 Flow,以及独家使用 Agent Mode 以及 YouTube Premium 和 30TB 存储空间,现已在美国推出,更多国家即将推出
- 美国、英国、巴西、印度尼西亚和日本的大学生可以免费获得一学年的 Google AI Pro
Chrome 和代理模式下的 Gemini
- Chrome 中的 Gemini 正在桌面上推出,供美国(英语)的 Google AI Pro 和 Ultra 用户使用,以便您可以总结、澄清和获取您正在阅读的任何网页的帮助,并通过隐私控制使 Gemini 仅在您提出要求时采取行动
- 代理模式即将面向 Ultra 桌面用户推出,该模式允许 Gemini 使用 MCP 协议和自动导航在线处理复杂的目标,例如筛选列表、填写表格或根据搜索结果进行安排
人工智能在搜索中的应用
- AI 模式将以新标签页的形式在 Google 搜索中向所有美国用户推出,该模式由 Gemini 2.5 提供支持,提供更高级的推理、更长的查询、多模式搜索和即时的高质量答案,其中的“深度搜索”可同时进行数百次搜索并综合引用的报告
- Project Astra 的实时功能(指向你的相机,询问你所看到的内容)、Project Mariner 的代理工具(购买门票、进行预订、管理任务)以及 Gmail 或其他 Google 应用的个人上下文将进入 AI 模式,由用户控制
Gemini 2.5
- Gemini 2.5 Pro 和 2.5 Flash 是领先的编码和推理基准,Gemini 2.5 Flash 有一个新的预览版本,具有更好的速度、效率和编码/推理能力,两种型号都将于 2025 年 6 月全面上市
- Gemini 2.5 Pro Deep Think 引入了一种实验性的增强推理模式,包括用于复杂任务的并行思维技术,在全面推出之前,首先通过 Gemini API 向值得信赖的测试人员推出,然后让用户控制答案深度和速度的思考预算
- Gemini API 和 SDK 原生支持模型上下文协议 (MCP),从而可以更轻松地跨系统集成代理和工具
- Gemini API 和 Vertex AI 现在提供“思想摘要”,逐步解释 Gemini 的推理和工具使用
Project Starline -> Google Beam、Astra -> Gemini Live、Mariner ->特工模式
- Starline 项目现已更名为 Google Beam,这是一个由人工智能驱动的 3D 视频通话平台,可将 2D 流媒体转化为身临其境的逼真会议,并将于今年晚些时候与惠普和其他企业合作伙伴合作推出
- Gemini Live 内置 Astra 的实时摄像头和屏幕共享功能,这些功能已在 Android 上免费提供,现已在 iOS 上推出
- Project Mariner 的代理计算机使用功能(例如多任务处理和浏览器自动化)现已面向美国 Ultra 用户开放,并将很快通过 Gemini API 和 Vertex AI 面向开发者开放
开放模型和开发工具
Gemma 3n 是一种新型高效多模态开放模型,专为快速、低内存设备设计,支持文本、音频、图像和多语言输入,目前已在 AI Studio 和 AI Edge 上为开发者提供预览版。
- Jules 是一款由 Gemini 2.5 Pro 提供支持的异步编码代理,目前处于公开测试阶段,并且免费,可在 GitHub 或您的 repo 中处理实际的编码任务,并具有并发任务和音频更新日志
- Gemini Diffusion 是一种用于快速文本生成的实验性研究模型,其输出速度约为 Google 之前最快模型的五倍,目前已通过候补名单向开发者提供预览。
SynthID Detector 是一个用于检查图像、音频、视频或文本是否由 Google 的 AI 工具生成的门户,目前正通过候补名单向早期测试人员推出,后续将提供更广泛的访问权限
#Google
https://x.com/btibor91/status/1924938391478468754?s=46&t=Egk_JeNH7VpTJDgz1k_q5w
https://blog.google/technology/developers/google-io-2025-collection/
生成媒体
- Veo 3 是 Google 最先进的视频生成模型,能够创建带有音效甚至对话的视频,目前在美国,Google AI Ultra 订阅用户可以通过 Gemini 应用和 Flow 使用,也可以在 Vertex AI 上进行私人预览,并将在未来几周内更广泛地推出
- Veo 2 正在获得新功能,例如参考驱动的视频(用于一致的风格和角色)、用于精确镜头调整的相机控制、用于扩展纵横比的外画以及对象添加/删除,现在 Flow 中提供了一些新控件,而 Vertex AI 即将提供全套控件
- Imagen 4 可生成更丰富、更细致、更准确的图像,改进文本渲染和快速结果,现已在 Gemini 应用程序、Whisk、Workspace(幻灯片、文档、视频)和 Vertex AI 中免费提供,新的快速版本即将推出
- Flow 是一款全新的 AI 电影制作工具,可让您通过自然语言和资产管理,使用 Veo、Imagen 和 Gemini 创建电影剪辑;现在可供美国的 Google AI Pro 和 Ultra 订阅用户使用
- Google 的音乐生成模型 Lyria 2 现已在 Vertex AI 中上线,用于高保真自适应音乐生成,Lyria RealTime 可作为实验性交互式音乐模型通过 Gemini API 和 Google AI Studio 使用,用于实时创作和演奏生成音乐
Gemini 应用程序
- Canvas 新增一键“创建”按钮,可轻松将聊天内容转换为交互式内容,例如信息图表、测验和 45 种语言的播客,而 Deep Research 现在可让您上传文件和图像,并且即将推出 Google Drive 和 Gmail 集成
- Gemini Live 相机和屏幕共享功能现已在 Android 和 iOS 上免费提供(正在推出),并将很快与日历、Keep、地图和 Tasks 等 Google 应用集成
订阅
- Google AI Pro(每月 19.99 美元)可在美国和其他国家/地区使用,但一些最新功能(如 Chrome 中的 Flow 或 Gemini)将首先在美国推出,并计划在更广泛的范围内推出
- Google AI Ultra(249.99 美元/月,新用户前三个月可享受 50% 的优惠)提供最高的使用限制、最早使用 Veo 3 和 Gemini 2.5 Pro Deep Think 等高级模型、最高限制的 Flow,以及独家使用 Agent Mode 以及 YouTube Premium 和 30TB 存储空间,现已在美国推出,更多国家即将推出
- 美国、英国、巴西、印度尼西亚和日本的大学生可以免费获得一学年的 Google AI Pro
Chrome 和代理模式下的 Gemini
- Chrome 中的 Gemini 正在桌面上推出,供美国(英语)的 Google AI Pro 和 Ultra 用户使用,以便您可以总结、澄清和获取您正在阅读的任何网页的帮助,并通过隐私控制使 Gemini 仅在您提出要求时采取行动
- 代理模式即将面向 Ultra 桌面用户推出,该模式允许 Gemini 使用 MCP 协议和自动导航在线处理复杂的目标,例如筛选列表、填写表格或根据搜索结果进行安排
人工智能在搜索中的应用
- AI 模式将以新标签页的形式在 Google 搜索中向所有美国用户推出,该模式由 Gemini 2.5 提供支持,提供更高级的推理、更长的查询、多模式搜索和即时的高质量答案,其中的“深度搜索”可同时进行数百次搜索并综合引用的报告
- Project Astra 的实时功能(指向你的相机,询问你所看到的内容)、Project Mariner 的代理工具(购买门票、进行预订、管理任务)以及 Gmail 或其他 Google 应用的个人上下文将进入 AI 模式,由用户控制
Gemini 2.5
- Gemini 2.5 Pro 和 2.5 Flash 是领先的编码和推理基准,Gemini 2.5 Flash 有一个新的预览版本,具有更好的速度、效率和编码/推理能力,两种型号都将于 2025 年 6 月全面上市
- Gemini 2.5 Pro Deep Think 引入了一种实验性的增强推理模式,包括用于复杂任务的并行思维技术,在全面推出之前,首先通过 Gemini API 向值得信赖的测试人员推出,然后让用户控制答案深度和速度的思考预算
- Gemini API 和 SDK 原生支持模型上下文协议 (MCP),从而可以更轻松地跨系统集成代理和工具
- Gemini API 和 Vertex AI 现在提供“思想摘要”,逐步解释 Gemini 的推理和工具使用
Project Starline -> Google Beam、Astra -> Gemini Live、Mariner ->特工模式
- Starline 项目现已更名为 Google Beam,这是一个由人工智能驱动的 3D 视频通话平台,可将 2D 流媒体转化为身临其境的逼真会议,并将于今年晚些时候与惠普和其他企业合作伙伴合作推出
- Gemini Live 内置 Astra 的实时摄像头和屏幕共享功能,这些功能已在 Android 上免费提供,现已在 iOS 上推出
- Project Mariner 的代理计算机使用功能(例如多任务处理和浏览器自动化)现已面向美国 Ultra 用户开放,并将很快通过 Gemini API 和 Vertex AI 面向开发者开放
开放模型和开发工具
Gemma 3n 是一种新型高效多模态开放模型,专为快速、低内存设备设计,支持文本、音频、图像和多语言输入,目前已在 AI Studio 和 AI Edge 上为开发者提供预览版。
- Jules 是一款由 Gemini 2.5 Pro 提供支持的异步编码代理,目前处于公开测试阶段,并且免费,可在 GitHub 或您的 repo 中处理实际的编码任务,并具有并发任务和音频更新日志
- Gemini Diffusion 是一种用于快速文本生成的实验性研究模型,其输出速度约为 Google 之前最快模型的五倍,目前已通过候补名单向开发者提供预览。
SynthID Detector 是一个用于检查图像、音频、视频或文本是否由 Google 的 AI 工具生成的门户,目前正通过候补名单向早期测试人员推出,后续将提供更广泛的访问权限
https://x.com/btibor91/status/1924938391478468754?s=46&t=Egk_JeNH7VpTJDgz1k_q5w
https://blog.google/technology/developers/google-io-2025-collection/

YT Navigator - AI 驱动的 YouTube 内容探索工具
https://github.com/wassim249/YT-Navigator
YT Navigator 是一个基于 AI 的应用程序,高效地浏览和搜索 YouTube 频道内容。
用自然语言搜索频道视频、与频道内容进行聊天对话,并发现相关的视频片段及其精确时间戳。
项目适用于研究人员、学生、内容创作者或任何需要快速从 YouTube 频道中提取信息的人。
1. 频道数据检索: 用户输入 YouTube 频道 URL,系统会提取频道详细信息并存储在数据库中。
2. 频道内容查询: 用户输入自然语言查询,系统会通过语义搜索和关键字搜索返回相关视频片段。
3. 与频道聊天: 用户可以与一个 AI 代理进行对话,该代理拥有频道内容的知识。
#AI #GitHub #Tool #Google
https://github.com/wassim249/YT-Navigator
YT Navigator 是一个基于 AI 的应用程序,高效地浏览和搜索 YouTube 频道内容。
用自然语言搜索频道视频、与频道内容进行聊天对话,并发现相关的视频片段及其精确时间戳。
项目适用于研究人员、学生、内容创作者或任何需要快速从 YouTube 频道中提取信息的人。
1. 频道数据检索: 用户输入 YouTube 频道 URL,系统会提取频道详细信息并存储在数据库中。
2. 频道内容查询: 用户输入自然语言查询,系统会通过语义搜索和关键字搜索返回相关视频片段。
3. 与频道聊天: 用户可以与一个 AI 代理进行对话,该代理拥有频道内容的知识。
#AI #GitHub #Tool #Google
DocTranslator - 文档翻译
免费在线文档翻译服务,支持将办公文档如 Word、PDF、Excel、PowerPoint、 OpenOffice 和文本文件翻译成多种语言,同时完美保留原始排版
只需将文件拖拽上传,系统会自动检测原始语言并将其翻译为目标语言
https://www.onlinedoctranslator.com/zh-CN/translationform#google_vignette
#URL #PDF #Tool
免费在线文档翻译服务,支持将办公文档如 Word、PDF、Excel、PowerPoint、 OpenOffice 和文本文件翻译成多种语言,同时完美保留原始排版
只需将文件拖拽上传,系统会自动检测原始语言并将其翻译为目标语言
https://www.onlinedoctranslator.com/zh-CN/translationform#google_vignette
#URL #PDF #Tool
Google One AI Premium 大学生免费
Gemini Advanced AI + Google Drive 2T 存储
https://gemini.google/students/
申请成功后 15 个月免费,15 个月过后按照原价 $ 20 每月收费
在免费期结束前随时取消,避免扣费
优惠申请截止日期:2025年6月30日
限定美国地区针已验证的 18 岁及以上学生(教育邮箱
1. 去这个网址查看自己的 Google 账号是否为美国,如果非美国建议重新注册账号
https://policies.google.com/country-association-form
2. 去这个网址登陆你自己的 Google 账号
https://gemini.google/students
3. 网站会要求你提供 edu 邮箱,并接受验证码
后面就是绑定付款和手机号之类的了,付款可以美区 PayPal (支持招商银行双币卡、外币卡),手机号可以用 Ultra Mobile 之类的实体卡
#AI #Free #Google
Gemini Advanced AI + Google Drive 2T 存储
https://gemini.google/students/
申请成功后 15 个月免费,15 个月过后按照原价 $ 20 每月收费
在免费期结束前随时取消,避免扣费
优惠申请截止日期:2025年6月30日
限定美国地区针已验证的 18 岁及以上学生(教育邮箱
1. 去这个网址查看自己的 Google 账号是否为美国,如果非美国建议重新注册账号
https://policies.google.com/country-association-form
2. 去这个网址登陆你自己的 Google 账号
https://gemini.google/students
3. 网站会要求你提供 edu 邮箱,并接受验证码
后面就是绑定付款和手机号之类的了,付款可以美区 PayPal (支持招商银行双币卡、外币卡),手机号可以用 Ultra Mobile 之类的实体卡
#AI #Free #Google

Google 推出 Agent2Agent(A2A)协议
Agent2Agent (A2A) 是一种新的开放协议,建立智能体之间的标准化协作框架。
A2A允许不同供应商或框架开发的AI智能体相互通信、安全交换信息并协调行动,覆盖文本、音视频流等多模态协作场景。
https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
#Google #AI
Agent2Agent (A2A) 是一种新的开放协议,建立智能体之间的标准化协作框架。
A2A允许不同供应商或框架开发的AI智能体相互通信、安全交换信息并协调行动,覆盖文本、音视频流等多模态协作场景。
https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
#Google #AI

第三方 YouTube Music 客户端
会员是不可能开的👋
https://github.com/th-ch/youtube-music
YouTube Music 是一个基于 Electron 的桌面应用程序,提供了丰富的自定义插件功能,包括广告拦截、下载器等。
该应用程序旨在保持原有的YouTube Music界面,同时提供了一个可扩展的框架,用户可以根据自己的需求定制应用程序的样式、内容和功能。
● 原生外观和感觉,保持原有的YouTube Music界面
● 支持自定义插件,用户可以根据需求启用/禁用插件
● 内置广告拦截器和下载器
● 支持多种主题定制
#GitHub #Tool #Music #Google
会员是不可能开的👋
https://github.com/th-ch/youtube-music
YouTube Music 是一个基于 Electron 的桌面应用程序,提供了丰富的自定义插件功能,包括广告拦截、下载器等。
该应用程序旨在保持原有的YouTube Music界面,同时提供了一个可扩展的框架,用户可以根据自己的需求定制应用程序的样式、内容和功能。
● 原生外观和感觉,保持原有的YouTube Music界面
● 支持自定义插件,用户可以根据需求启用/禁用插件
● 内置广告拦截器和下载器
● 支持多种主题定制
#GitHub #Tool #Music #Google
my-yt - YouTube 第三方 Web 客户端
https://github.com/christian-fei/my-yt
my-yt 是一个干净简约的 YouTube 前端,没有广告和其他干扰元素。
它使用yt-dlp下载视频,并可选地使用本地AI模型或托管服务(如OpenAI)对视频内容进行总结。
它还提供了频道管理、离线播放、Chromecast支持、去除赞助内容等功能,为用户提供了更加专注和高效的YouTube观看体验。
● 频道管理和订阅
● 使用yt-dlp下载YouTube视频
● 忽略不想观看的视频
● 自动移除赞助内容(借助SponsorBlock)
● 离线媒体播放
● 原生Google Chromecast支持
● 禁用点击诱饵缩略图
● 后台播放视频
● 使用本地AI模型或托管服务(如OpenAI)总结视频内容
● 原生画中画支持
● 无依赖(除了nano-spawn,它本身没有传递依赖)
● 仅使用HTML/CSS,客户端/服务器端无JS框架
● 使用track元素和WebVTT API支持字幕
#GitHub #Google #Video
https://github.com/christian-fei/my-yt
my-yt 是一个干净简约的 YouTube 前端,没有广告和其他干扰元素。
它使用yt-dlp下载视频,并可选地使用本地AI模型或托管服务(如OpenAI)对视频内容进行总结。
它还提供了频道管理、离线播放、Chromecast支持、去除赞助内容等功能,为用户提供了更加专注和高效的YouTube观看体验。
● 频道管理和订阅
● 使用yt-dlp下载YouTube视频
● 忽略不想观看的视频
● 自动移除赞助内容(借助SponsorBlock)
● 离线媒体播放
● 原生Google Chromecast支持
● 禁用点击诱饵缩略图
● 后台播放视频
● 使用本地AI模型或托管服务(如OpenAI)总结视频内容
● 原生画中画支持
● 无依赖(除了nano-spawn,它本身没有传递依赖)
● 仅使用HTML/CSS,客户端/服务器端无JS框架
● 使用track元素和WebVTT API支持字幕
#GitHub #Google #Video
YT PRO - Android 轻量级 YouTube 客户端
https://github.com/prateek-chaubey/YTPRO
YTPro 是一款功能强大的 YouTube 应用程序,提供了多种增强功能,包括视频下载、背景播放、广告拦截等。
该项目旨在通过 JavaScript 注入到 WebView 中来提高用户的生产力。
● 视频摘要和定制提示
● 视频下载器
● 短视频下载器
● 缩略图下载器
● 字幕下载器
● 广告拦截器
● 最小化视频
● 画中画模式
● 显示点赞数
● 后台音频播放器
● 自定义收藏功能
● 跳过赞助内容
● 强制缩放
● 隐藏短视频
● 小于 50KB 的 APK 大小
● 最小化设计
● 几乎没有内部依赖
● 自动更新应用程序
● Gemini AI 总结视频
#Android #GitHub #Google #Video
https://github.com/prateek-chaubey/YTPRO
YTPro 是一款功能强大的 YouTube 应用程序,提供了多种增强功能,包括视频下载、背景播放、广告拦截等。
该项目旨在通过 JavaScript 注入到 WebView 中来提高用户的生产力。
● 视频摘要和定制提示
● 视频下载器
● 短视频下载器
● 缩略图下载器
● 字幕下载器
● 广告拦截器
● 最小化视频
● 画中画模式
● 显示点赞数
● 后台音频播放器
● 自定义收藏功能
● 跳过赞助内容
● 强制缩放
● 隐藏短视频
● 小于 50KB 的 APK 大小
● 最小化设计
● 几乎没有内部依赖
● 自动更新应用程序
● Gemini AI 总结视频
#Android #GitHub #Google #Video
Gemma3 – 当前最强大的单GPU模型
Gemma3 是当前最强大的单GPU模型。该模型的参数有四种规格可供选择:1B、4B、12B和27B,适用于不同的任务需求。Gemma3 是基于Google的Gemini技术构建的轻量级多模态模型,可以处理文本和图像,支持超过140种语言,并提供128K的上下文窗口。其设计紧凑,适合在资源有限的设备上部署。
在模型参数方面,具体的指标如下:
• 1B参数模型(32k上下文窗口)
• 4B参数模型(128k上下文窗口)
• 12B参数模型(128k上下文窗口)
• 27B参数模型(128k上下文窗口)
模型在文本生成方面的表现经过一系列基准测试进行评估,涵盖推理、逻辑和代码能力等不同方面。根据不同数据集和评估指标,Gemma3在各个参数规格下的表现如下:
• HellaSwag:1B为62.3,4B为77.2,12B为84.2,27B为85.6
• BoolQ:1B为63.2,4B为72.3,12B为78.8,27B为82.4
• PIQA:1B为73.8,4B为79.6,12B为81.8,27B为83.3
• 其他数据集的表现也在不同参数下有所不同,全面展示了Gemma3在处理语言任务时的强大能力。
在多模态能力的评估中,4B、12B和27B参数模型在多项指标上也显示出优越表现,如COCOcap、DocVQA等测试中均取得了理想的分数。
最后,需要注意的是,使用Gemma3模型需遵循Gemma使用条款,并要求安装Ollama 0.6或更高版本。
https://ollama.com/library/gemma3
https://news.ycombinator.com/item?id=43340785
#AI #Google link
Gemma3 是当前最强大的单GPU模型。该模型的参数有四种规格可供选择:1B、4B、12B和27B,适用于不同的任务需求。Gemma3 是基于Google的Gemini技术构建的轻量级多模态模型,可以处理文本和图像,支持超过140种语言,并提供128K的上下文窗口。其设计紧凑,适合在资源有限的设备上部署。
在模型参数方面,具体的指标如下:
• 1B参数模型(32k上下文窗口)
• 4B参数模型(128k上下文窗口)
• 12B参数模型(128k上下文窗口)
• 27B参数模型(128k上下文窗口)
模型在文本生成方面的表现经过一系列基准测试进行评估,涵盖推理、逻辑和代码能力等不同方面。根据不同数据集和评估指标,Gemma3在各个参数规格下的表现如下:
• HellaSwag:1B为62.3,4B为77.2,12B为84.2,27B为85.6
• BoolQ:1B为63.2,4B为72.3,12B为78.8,27B为82.4
• PIQA:1B为73.8,4B为79.6,12B为81.8,27B为83.3
• 其他数据集的表现也在不同参数下有所不同,全面展示了Gemma3在处理语言任务时的强大能力。
在多模态能力的评估中,4B、12B和27B参数模型在多项指标上也显示出优越表现,如COCOcap、DocVQA等测试中均取得了理想的分数。
最后,需要注意的是,使用Gemma3模型需遵循Gemma使用条款,并要求安装Ollama 0.6或更高版本。
https://ollama.com/library/gemma3
https://news.ycombinator.com/item?id=43340785
#AI #Google link
Google Gemini 2.0 的 thinking 模型每个对话的 Token 上限提高到 100 万,相较之前有进步,但某些时候还是比 DeepSeek R1 要差点意思
https://aistudio.google.com/prompts/new_chat
#AI #Google
https://aistudio.google.com/prompts/new_chat
#AI #Google
Google Gemini
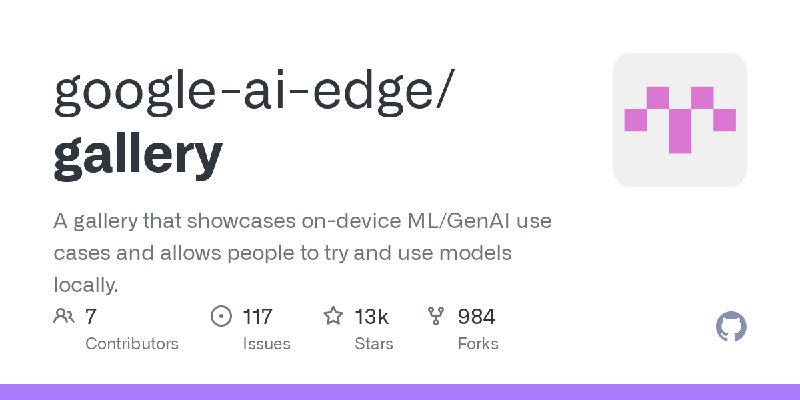
https://github.com/google-gemini/multimodal-live-api-web-console
基于React,通过WebSocket使用Multimodal Live API。它提供了流式音频播放、录制用户媒体(如麦克风、网络摄像头或屏幕捕获)以及统一日志视图等功能,以帮助开发人员构建应用程序
https://github.com/google-gemini/cookbook
关于 Gemini API 的 cookbook,提供了各种使用 Gemini API 的指南和示例。Gemini API 是由 Google DeepMind 开发的一个多模态 API,可以处理文本、图像、代码和音频等数据。
#GitHub #Google #AI
https://github.com/google-gemini/multimodal-live-api-web-console
基于React,通过WebSocket使用Multimodal Live API。它提供了流式音频播放、录制用户媒体(如麦克风、网络摄像头或屏幕捕获)以及统一日志视图等功能,以帮助开发人员构建应用程序
https://github.com/google-gemini/cookbook
关于 Gemini API 的 cookbook,提供了各种使用 Gemini API 的指南和示例。Gemini API 是由 Google DeepMind 开发的一个多模态 API,可以处理文本、图像、代码和音频等数据。
#GitHub #Google #AI