


👋 动态记录 & 转发分享 ✨ https://tg.okhk.net/ ✌️
k8s 部署 mihomo(former clash-meta) 作为内网的透明网关
#RePost #K8s #GitHub #Network
写了份指南,
实现了在 k8s 集群上部署 mihomo ,让 mihomo 作为透明网关接管内网流量
用到了 multus 将 pod 的网卡暴露到内网
用起来还不错,不需要 vm 这么重的方式部署透明网关了
pod 挂了还能自愈,主打一个一劳永逸。
https://github.com/Winson-030/mihomo-kubernetes
https://www.v2ex.com/t/1043922#reply0
Message link
#RePost #K8s #GitHub #Network
写了份指南,
实现了在 k8s 集群上部署 mihomo ,让 mihomo 作为透明网关接管内网流量
用到了 multus 将 pod 的网卡暴露到内网
用起来还不错,不需要 vm 这么重的方式部署透明网关了
pod 挂了还能自愈,主打一个一劳永逸。
https://github.com/Winson-030/mihomo-kubernetes
https://www.v2ex.com/t/1043922#reply0
Message link
#RePost #K8s #DevOps
关于 k8s 的 zero downtime deployment 一些建议 https://wklken.me/posts/2023/12/17/some-tips-for-zero-downtime-deployment.html
滚动更新配置防止 502 的一些方式:
● 配置 liveness/readiness
● 配置 terminationGracePeriodSeconds
● 程序需要支持 graceful shutdown
● 主进程 pid 为 1,可以收到信号
● 通过配置 preStop 来保证 service endpoint 变更和 pod 删除的变更顺序
不过如果在滚动更新过程中遇到问题,需要终止,好像还是采用两套 deployment 在接入层切换多一些。
关于 k8s 的 zero downtime deployment 一些建议 https://wklken.me/posts/2023/12/17/some-tips-for-zero-downtime-deployment.html
滚动更新配置防止 502 的一些方式:
● 配置 liveness/readiness
● 配置 terminationGracePeriodSeconds
● 程序需要支持 graceful shutdown
● 主进程 pid 为 1,可以收到信号
● 通过配置 preStop 来保证 service endpoint 变更和 pod 删除的变更顺序
不过如果在滚动更新过程中遇到问题,需要终止,好像还是采用两套 deployment 在接入层切换多一些。
#K8s #RePost #DevOps 从滴滴的故障中我们能学到什么 https://mp.weixin.qq.com/s/Oj4qGrYHq9-z87H2b9WDzg
● 控制规模,用多个小规模 K8s 集群的联邦代替一个大 K8s
● 避免单点,一个 K8s 集群也应该被视作一个单点
● 拥抱重启,把重启和迁移视作常态
● 数据面的可用性和控制面要解耦
● 控制规模,用多个小规模 K8s 集群的联邦代替一个大 K8s
● 避免单点,一个 K8s 集群也应该被视作一个单点
● 拥抱重启,把重启和迁移视作常态
● 数据面的可用性和控制面要解耦
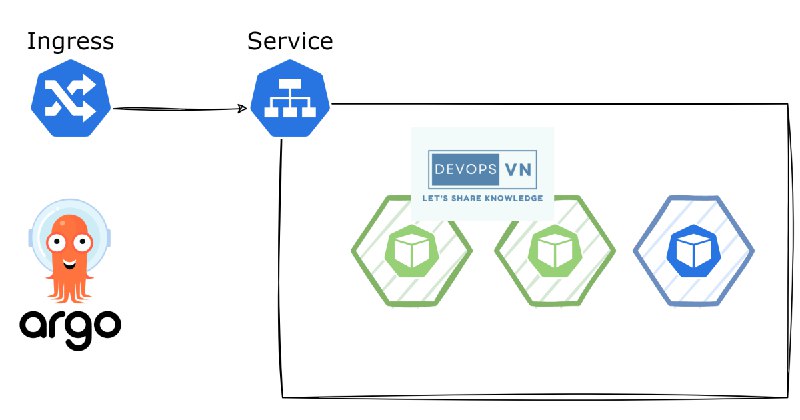
Kubernetes Practice — Automating Blue/Green Deployment with Argo Rollouts gpt: 这篇文章介绍了如何使用Argo Rollouts自动化在Kubernetes上进行蓝绿部署。Argo Rollouts提供了一些比原生Kubernetes部署对象更高级的功能,如蓝绿部署、金丝雀部署、金丝雀分析、实验和渐进式交付功能。作者通过实例演示了如何在Kubernetes集群上安装和使用Argo Rollouts。
https://faun.pub/kubernetes-practice-automating-blue-green-deployment-with-argo-rollouts-2279aa890c53
#K8s #RePost #DevOps
https://faun.pub/kubernetes-practice-automating-blue-green-deployment-with-argo-rollouts-2279aa890c53
#K8s #RePost #DevOps
#DevOps #RePost #K8s
● Using Argo CD and Kustomize for ConfigMap Rollouts gpt: 这篇文章讲述了如何使用Argo CD和Kustomize解决Kubernetes中的ConfigMap更新不会触发应用部署的问题。主要方法是通过在Kustomize中使用commonAnnotations,在ConfigMap更新时改变注解值,从而触发应用的部署。这种方法也适用于Secrets和Sealed Secrets,是一种使用Kubernetes内置工具的简单解决方案。
https://codefresh.io/blog/using-argo-cd-and-kustomize-for-configmap-rollouts/
● How to Clean Up Old Containers and Images in Your Kubernetes Cluster gpt: 这篇文章介绍了如何在Kubernetes集群中清理旧的容器和镜像。Kubernetes内置的垃圾收集系统,由Kubelet管理,可以自动清理未使用的镜像和停止或无法识别的容器。用户可以通过设置Kubelet标志来自定义垃圾收集的运行时机和容器的保留期限。然而,手动删除死亡容器或镜像是不推荐的,因为可能会导致Kubelet的运行出现问题。未来,Kubernetes计划用更强大的"驱逐"系统来替代垃圾收集,这将提供一种统一的方式来清理Kubernetes资源。
https://www.howtogeek.com/devops/how-to-clean-up-old-containers-and-images-in-your-kubernetes-cluster/
● helm-dashboard Helm Dashboard是一个开源项目,它提供了一种 UI 驱动的方式来查看已安装的 Helm 图表、查看其修订历史记录和相应的 k8s 资源。它还允许用户执行简单的操作,例如回滚到修订版或升级到更新版本。
https://github.com/komodorio/helm-dashboard
learnkubernetes.withgoogle.com 谷歌推出的一系列k8s教学视频
https://learnkubernetes.withgoogle.com/
source
● Using Argo CD and Kustomize for ConfigMap Rollouts gpt: 这篇文章讲述了如何使用Argo CD和Kustomize解决Kubernetes中的ConfigMap更新不会触发应用部署的问题。主要方法是通过在Kustomize中使用commonAnnotations,在ConfigMap更新时改变注解值,从而触发应用的部署。这种方法也适用于Secrets和Sealed Secrets,是一种使用Kubernetes内置工具的简单解决方案。
https://codefresh.io/blog/using-argo-cd-and-kustomize-for-configmap-rollouts/
● How to Clean Up Old Containers and Images in Your Kubernetes Cluster gpt: 这篇文章介绍了如何在Kubernetes集群中清理旧的容器和镜像。Kubernetes内置的垃圾收集系统,由Kubelet管理,可以自动清理未使用的镜像和停止或无法识别的容器。用户可以通过设置Kubelet标志来自定义垃圾收集的运行时机和容器的保留期限。然而,手动删除死亡容器或镜像是不推荐的,因为可能会导致Kubelet的运行出现问题。未来,Kubernetes计划用更强大的"驱逐"系统来替代垃圾收集,这将提供一种统一的方式来清理Kubernetes资源。
https://www.howtogeek.com/devops/how-to-clean-up-old-containers-and-images-in-your-kubernetes-cluster/
● helm-dashboard Helm Dashboard是一个开源项目,它提供了一种 UI 驱动的方式来查看已安装的 Helm 图表、查看其修订历史记录和相应的 k8s 资源。它还允许用户执行简单的操作,例如回滚到修订版或升级到更新版本。
https://github.com/komodorio/helm-dashboard
learnkubernetes.withgoogle.com 谷歌推出的一系列k8s教学视频
https://learnkubernetes.withgoogle.com/
source
#DevOps #K8s #RePost https://twitter.com/halfbloodrock/status/1729876674786070751 趁着滴滴宕机10小时,都说是Kubernetes升级引起的,刚好kubernetes是老本行,在eBay那几年,都是在做大规模kubernetes集群管理,kubernetes集群升级这块,正好蹭个热点,讲讲这几年在kubernetes上踩过的坑。
kubernetes 升级遇到的坑汇总:
● ip pool block要是配小了,很可能出现pod拿不到IP起不来而计算资源空闲的情况。调度器可不看IPAM里还有多少剩余IP
● 为啥要改k8s代码?For KPI? k8s一直到1.12才趋于稳定,比如admission webhook是1.9才引入,到1.13稳定 之前admission上的一些需求只能改上游代码,改动提给社区,人家不一定要,而后面版本cherrypick这些自己改的代码,维护起来还是比较痛苦的。 不过到今天绝大部分需求都不用再改上游代码
● 改了上游代码,最好的结果是,提给社区合并进主干。但是大部分情况是提上去的社区不接受,原因众多。 那在下个大版本升级时候,需要把改过的代码cherry-pick进去,解决冲突,过UT,过e2e,过benchmark
● k8s可以应用无感知升级吗? 至少1.18之前不行 Kubelet升级之后要重新算下pod hash,会重建底层容器,不少应用其实不太能容忍这个动作,每次升级都要收到很多pod重启的抱怨
● 有状态应用到底能不能上k8s? k8s的statefulset解决的是pod启动顺序问题,其实真正的核心点是有状态应用如何存数据。 像es这种天生分布式的,可采用本地lvm卷做存储https://github.com/openebs/lvm-localpv… 像MySQL,官方推荐的是mysql cluster+proxy (但是我没在生产上跑过) https://github.com/mysql/mysql-operator
● 为啥一升级就挂?k8s里有两个地方变动相对频繁,一个是feature gate,一个是api-version 问题七中的坑,1.10之前可以disable这个feature gate,但是1.10之后强制打开,没有disable的机会。 升级过程中发现了,用户改代码没那么快咋办?只能把上游的这个commit 去掉
● 能跨版本升级吗?能跨多少版本? 不要跨超过三个版本:https://kubernetes.io/zh-cn/releases/version-skew-policy/… 熟读ChangeLog 曾经的坑,用户在pod里对secret做修改,1.10之后社区去除了这个功能,这直挺挺升级上去用户应用就挂了。这些变动在每个版本ChangeLog里都有
source
kubernetes 升级遇到的坑汇总:
● ip pool block要是配小了,很可能出现pod拿不到IP起不来而计算资源空闲的情况。调度器可不看IPAM里还有多少剩余IP
● 为啥要改k8s代码?For KPI? k8s一直到1.12才趋于稳定,比如admission webhook是1.9才引入,到1.13稳定 之前admission上的一些需求只能改上游代码,改动提给社区,人家不一定要,而后面版本cherrypick这些自己改的代码,维护起来还是比较痛苦的。 不过到今天绝大部分需求都不用再改上游代码
● 改了上游代码,最好的结果是,提给社区合并进主干。但是大部分情况是提上去的社区不接受,原因众多。 那在下个大版本升级时候,需要把改过的代码cherry-pick进去,解决冲突,过UT,过e2e,过benchmark
● k8s可以应用无感知升级吗? 至少1.18之前不行 Kubelet升级之后要重新算下pod hash,会重建底层容器,不少应用其实不太能容忍这个动作,每次升级都要收到很多pod重启的抱怨
● 有状态应用到底能不能上k8s? k8s的statefulset解决的是pod启动顺序问题,其实真正的核心点是有状态应用如何存数据。 像es这种天生分布式的,可采用本地lvm卷做存储https://github.com/openebs/lvm-localpv… 像MySQL,官方推荐的是mysql cluster+proxy (但是我没在生产上跑过) https://github.com/mysql/mysql-operator
● 为啥一升级就挂?k8s里有两个地方变动相对频繁,一个是feature gate,一个是api-version 问题七中的坑,1.10之前可以disable这个feature gate,但是1.10之后强制打开,没有disable的机会。 升级过程中发现了,用户改代码没那么快咋办?只能把上游的这个commit 去掉
● 能跨版本升级吗?能跨多少版本? 不要跨超过三个版本:https://kubernetes.io/zh-cn/releases/version-skew-policy/… 熟读ChangeLog 曾经的坑,用户在pod里对secret做修改,1.10之后社区去除了这个功能,这直挺挺升级上去用户应用就挂了。这些变动在每个版本ChangeLog里都有
source
#K8s #RePost #DevOps
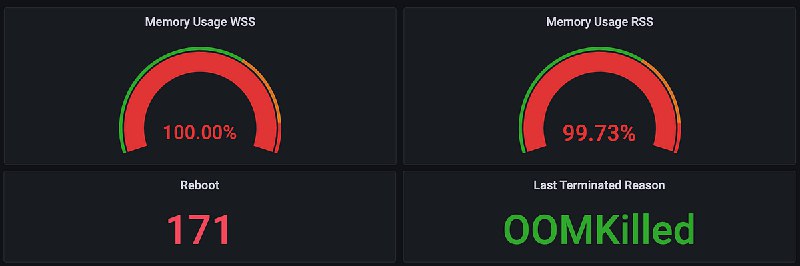
● Memory settings for Java process running in Kubernetes pod gpt: 这篇文章探讨了在Kubernetes pod中运行Java进程的内存管理挑战。尽管正确配置了JVM内存设置,仍可能出现OOMKilled问题。作者提出,由于JVM只限制堆内存大小,而非堆内存会取决于多种因素,因此无法确保Java进程的完全内存边界。他建议从堆内存到非堆内存的75%比例开始,并密切关注内存行为。如果问题仍然存在,可以调整pod的内存限制或调整堆到非堆的比例。他还分享了他们在处理这个问题的过程中遇到的问题和解决方法,并提出了一些问题的分析和解答。
https://medium.com/@sharprazor.app/memory-settings-for-java-process-running-in-kubernetes-pod-1e608a5d2a64
第一次碰到-XX:MaxRAMPercentage=80.0这个参数
● How to Achieve Zero-Downtime Application with Kubernetes gpt: 这篇文章讨论了如何通过Kubernetes实现应用程序的零停机时间。作者强调了容器对托管环境的巨大改变,并解释了如何利用Kubernetes的特性来构建完美的应用程序生命周期设置。文章详细阐述了实现零停机时间应用程序所需的各种策略和技术,包括容器镜像位置、Pod的数量、Pod破坏预算、部署策略、自动回滚部署、探测器、初始启动时间延迟、优雅的终止期、Pod反亲和性、资源和自动扩展等。文章还强调了为什么这些配置对于实现零停机时间应用程序至关重要,并提供了在不同情况下应该如何调整这些配置以优化结果。
https://www.qovery.com/blog/how-to-achieve-zero-downtime-application-with-kubernetes
source
● Memory settings for Java process running in Kubernetes pod gpt: 这篇文章探讨了在Kubernetes pod中运行Java进程的内存管理挑战。尽管正确配置了JVM内存设置,仍可能出现OOMKilled问题。作者提出,由于JVM只限制堆内存大小,而非堆内存会取决于多种因素,因此无法确保Java进程的完全内存边界。他建议从堆内存到非堆内存的75%比例开始,并密切关注内存行为。如果问题仍然存在,可以调整pod的内存限制或调整堆到非堆的比例。他还分享了他们在处理这个问题的过程中遇到的问题和解决方法,并提出了一些问题的分析和解答。
https://medium.com/@sharprazor.app/memory-settings-for-java-process-running-in-kubernetes-pod-1e608a5d2a64
第一次碰到-XX:MaxRAMPercentage=80.0这个参数
● How to Achieve Zero-Downtime Application with Kubernetes gpt: 这篇文章讨论了如何通过Kubernetes实现应用程序的零停机时间。作者强调了容器对托管环境的巨大改变,并解释了如何利用Kubernetes的特性来构建完美的应用程序生命周期设置。文章详细阐述了实现零停机时间应用程序所需的各种策略和技术,包括容器镜像位置、Pod的数量、Pod破坏预算、部署策略、自动回滚部署、探测器、初始启动时间延迟、优雅的终止期、Pod反亲和性、资源和自动扩展等。文章还强调了为什么这些配置对于实现零停机时间应用程序至关重要,并提供了在不同情况下应该如何调整这些配置以优化结果。
https://www.qovery.com/blog/how-to-achieve-zero-downtime-application-with-kubernetes
source
#URL #DevOps #K8s https://hervekhg.medium.com/3-years-managing-kubernetes-clusters-my-10-lessons-b565a5509f0e 作者描述他三年的 kubernetes 集群管理的十条经验
● 在云环境使用 kubernetes,这会比自己维护要简单很多,即便是自己维护也不会让自己的业务能力得到成长,或者收益性价比不高
● 使用代码来部署应用,避免直接在控制台用命令操作,这样难以记录操作。
● 避免过度使用 helm,同时要对充分理解其中的配置项;这个也很重要。
● 不要直接迁移应用到 kubernetes,往往需要做相关的适配。
● 非必要不要使用 Mesh
● 避免过多的使用管理工具,
● 一定要记得定义资源的限制(内存和 CPU),避免程序 bug 导致 kubernetes 集群出现问题
● 尽量不要在 Pod 中存储数据,推荐使用 NAS、云存储
● 配置 HPA,可以根据负载自动扩容 Pod
● 不要畏惧改变,每年需要对
source
● 在云环境使用 kubernetes,这会比自己维护要简单很多,即便是自己维护也不会让自己的业务能力得到成长,或者收益性价比不高
● 使用代码来部署应用,避免直接在控制台用命令操作,这样难以记录操作。
● 避免过度使用 helm,同时要对充分理解其中的配置项;这个也很重要。
● 不要直接迁移应用到 kubernetes,往往需要做相关的适配。
● 非必要不要使用 Mesh
● 避免过多的使用管理工具,
kubernetes 的管理工具有很多,但大部分操作就靠 kubectl 就够用了。● 一定要记得定义资源的限制(内存和 CPU),避免程序 bug 导致 kubernetes 集群出现问题
● 尽量不要在 Pod 中存储数据,推荐使用 NAS、云存储
● 配置 HPA,可以根据负载自动扩容 Pod
● 不要畏惧改变,每年需要对
kubernetes 进行升级,升级前需要充分阅读 ReleaseNote.source
